Description
A rooted tree is a well-known data structure in computer science and engineering. An example is shown below:
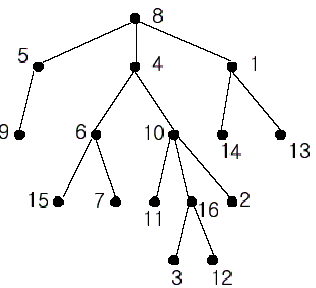
In the figure, each node is labeled with an integer from {1, 2,…,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
The input consists of T test cases. The number of test cases (T) is given in the first line of the input file. Each test case starts with a line containing an integer N , the number of nodes in a tree, 2<=N<=10,000. The nodes are labeled with integers 1, 2,…, N. Each of the next N -1 lines contains a pair of integers that represent an edge –the first integer is the parent node of the second integer. Note that a tree with N nodes has exactly N – 1 edges. The last line of each test case contains two distinct integers whose nearest common ancestor is to be computed.
Output
Print exactly one line for each test case. The line should contain the integer that is the nearest common ancestor.
Sample Input
2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 11 6 7 10 2 16 3 8 1 16 12 16 7 5 2 3 3 4 3 1 1 5 3 5
Sample Output
4 3
关于LCA和RMQ问题
一、最近公共祖先(Least Common Ancestors)
对于有根树T的两个结点u、v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u、v的祖先且x的深度尽可能大。另一种理解方式是把T理解为一个无向无环图,而LCA(T,u,v)即u到v的最短路上深度最小的点。
这里给出一个LCA的例子:
例一
对于T=<V,E>
V={1,2,3,4,5}
E={(1,2),(1,3),(3,4),(3,5)}
则有:
LCA(T,5,2)=1
LCA(T,3,4)=3
LCA(T,4,5)=3
二、RMQ问题(Range Minimum Query)
RMQ问题是指:对于长度为n的数列A,回答若干询问RMQ(A,i,j)(i,j<=n),返回数列A中下标在[i,j]里的最小值下标。这时一个RMQ问题的例子:
例二
对数列:5,8,1,3,6,4,9,5,7 有:
RMQ(2,4)=3
RMQ(6,9)=6
RMQ问题与LCA问题的关系紧密,可以相互转换,相应的求解算法也有异曲同工之妙。
下面给出LCA问题向RMQ问题的转化方法。
对树进行深度优先遍历,每当“进入”或回溯到某个结点时,将这个结点的深度存入数组E最后一位。同时记录结点i在数组中第一次出现的位置(事实上就是进入结点i时记录的位置),记做R[i]。如果结点E[i]的深度记做D[i],易见,这时求LCA(T,u,v),就等价于求E[RMQ(D,R[u],R[v])],(R[u]<R[v])。例如,对于第一节的例一,求解步骤如下:
数列E[i]为:1,2,1,3,4,3,5,3,1
R[i]为:1,2,4,5,7
D[i]为:0,1,0,1,2,1,2,1,0
于是有:
LCA(T,5,2) = E[RMQ(D,R[2],R[5])] = E[RMQ(D,2,7)] = E[3] = 1
LCA(T,3,4) = E[RMQ(D,R[3],R[4])] = E[RMQ(D,4,5)] = E[4] = 3
LCA(T,4,5) = E[RMQ(D,R[4],R[5])] = E[RMQ(D,5,7)] = E[6] = 3
易知,转化后得到的数列长度为树的结点数的两倍加一,所以转化后的RMQ问题与LCA问题的规模同次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | import java.util.Arrays; import java.util.Scanner; public class Main{ static final int maxn = 11000; static Nodee[] Edge = new Nodee[maxn]; static int[] head = new int[maxn]; static int[] q = new int[maxn]; static int[] f = new int[maxn]; static boolean[] vis = new boolean[maxn]; static int NE = 0; public static void main(String[] args) { Scanner cin = new Scanner(System.in); int t = cin.nextInt(); while(t--!=0){ int n = cin.nextInt(); NE = 0; Arrays.fill(head, -1); Arrays.fill(q, 0); Arrays.fill(f, 0); Arrays.fill(vis, false); int i ,j; for(int k = 1; k < n; k++){ i = cin.nextInt(); j = cin.nextInt(); addEdge(i, j); f[j]++;/// j 为叶子节点 } i = cin.nextInt(); j = cin.nextInt(); q[q[i]=j]=i; for(i=1;i<=n;i++){ if(f[i]==0)tarjan(i); } } } static void addEdge(int u,int v){ Edge[NE] = new Nodee(u,v,head[u]); head[u] = NE++; } static int find(int u){ if(f[u]==u)return u; else return f[u]=find(f[u]); } static boolean tarjan(int u){ if(q[u]!=0&&vis[q[u]]){///队列中有u 并且它的目标结点已经遍历过! System.out.println(find(q[u]));///并查集找到目标节点的父节点,即为最近公共祖先 return true; } /// f[u]=u;初始化 u 的父亲节点f[u]=u; vis[f[u]=u] = true;///并将此节点标记为以遍历 for(int i = head[u],v; i!=-1; i = Edge[i].next){//u的子节点个数 if(!vis[v=Edge[i].v]){//v 为 u 的 一个子节点,并且这个节点未被遍历过 if(tarjan(v))return true; f[v] = u;/// v 的父节点f[v] 赋值为 u; } } return false; } } class Nodee{ int u; int v; int next; public Nodee(int u,int v,int next){ this.u = u; this.v = v; this.next = next; } } |
除非注明,饮水思源博客文章均为原创,转载请以链接形式标明本文地址